MapReduce
Page content
MapReduce是三篇经典分布式论文中与关于批量计算的一篇,相比之下,MapReduce较为容易理解。对于MapReduce,我了解不够深入,仅限于阅读过论文,写过简单的HadoopMapReduce程序,完成了6.824的模拟例题。下面,我将会简单整理一下我对MapReduce的理解。
MapReduce编程模型
MapReduce分为两个阶段:Map阶段、Reduce阶段。
Map程序有成千上万个,一般情况运行在成千上万个机器上面。Map程序负责将用户数据读入,生成临时的key value pair。Reduce程序负责将生成的临时kv pair按照用户的意图聚合,最后写入指定地点。如下图所示:
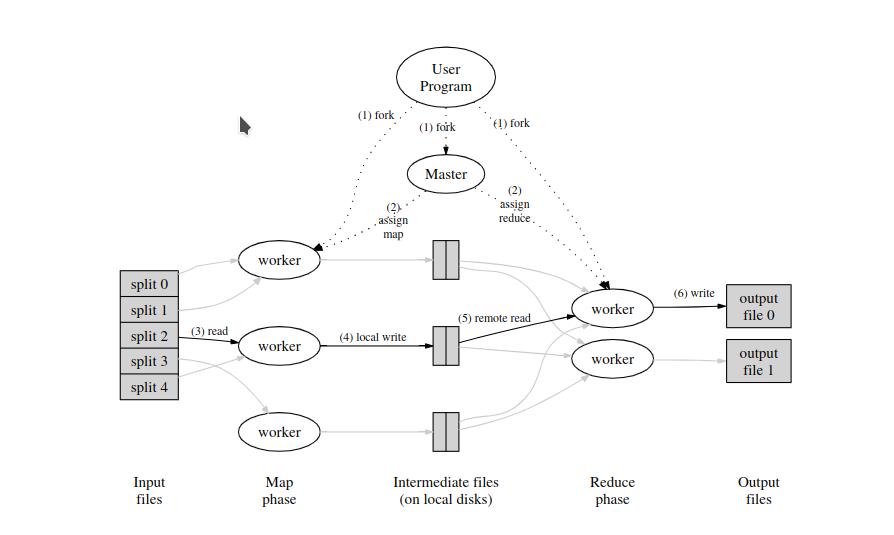
运行流程
- 用户将Job提交给Master
- Master负责分配任务给Map
- Map各自读取自己需要的数据,运行,将数据结果放到本地内存
- Map程序中,如果数据足够多时,flush到本地文件。Map程序最终产生R个临时文件。
- Map运行完成后,通知Master结果信息。
- Master通知Reduce程序运行,以及临时文件的位置。
- Reduce主动拉取文件。
- Reduce将结果写入到本地临时目录。
- Reduce运行完成后,将临时目录重命名为目标目录
- Reduce将运行结果通知Master
容错
Worker
- Master周期性ping每个worker,如果超时,则表示次work失效
- 失效的Map worker负责的所有mapreduce状态都将会被重置,并且重新调度,并通知相关的reduce worker
- 失效的Reduce worker,如果正在运行,则被重新调度,如果完成,则忽略。
Master
一般而言,都是直接失败。
调度优化
- 尽量将输入与Map worker放到本地或者邻近的地方
- 理论上M和R越大越好,但是实际得看具体情况
- 使用combiner