Fencing与脑裂
Page content

在使用ZK选主或者作为分布式锁的系统中,可能会出现脑裂问题。 原因可能是:
- 节点A的假死,会让ZK认为A是真死,所以将锁让给B。但是A并不认识自己已死,复活之后会继续写目标数据。
- ZK某些节点的假死,可能让两个节点都认为自己是Active节点。
所以,ZK解决不了脑裂问题。
HDFS NameNode如何解决脑裂问题
背景: HDFS的NameNode同时只能存在一个Active节点。
HDFS通过JournalNode来解决脑裂问题。
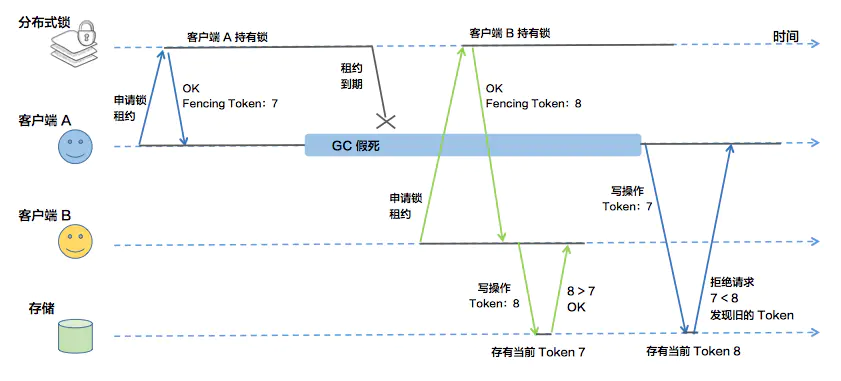
NameNode往JournalNode写edit log的时候,需要带上一个epoch,如果epoch比JournalNode的小,则会被拒绝。
- A节点为Active节点,假设Epoch是7
- A节点假死
- B节点被选为Active节点,Epoch加一,变成8,
- B节点写editlog,JournalNode更新epoch为8
- A节点复活,通过Epoch 7去写edit log,被拒绝,解决了脑裂问题。
小米云自研消息队列Talos是如何解决脑裂问题
背景:
- Talos需要保证同一条消息必须连续存储
- 同一个Partition里面的消息必须顺序存储。
所以要求:同一时刻,同一个Partition(HDFS目录)只能有一个Talos Server写入。
为了解决上面问题,Talos使用了ZK作为分布式锁,将TalosServer与Partition进行绑定。但是如最上所说,Zk无法解决脑裂问题:
- 如果A节点获取到了PartitionA的锁。
- A节点假死,锁TTL超时。
- B节点获取到Partition的锁。
- A节点复活,继续写这个Partition。
如此就有了脑裂问题。
Talos也是通过Fencing机制来解决脑裂问题。不过与HDFS NameNode形式稍有不同。
解决步骤:
- 节点A获取到锁
- A假死,锁TTL超时。
- B获取到锁,获取这个目录下所有的文件,将最后一个文件关闭,并且新建一个名字为{LastOffset+1}的文件,其中LastOffset为最后一个文件的最后一个消息的Offset。
- A复活,继续写文件,发现文件已经关闭,新建{LastOffset+1}的文件,发现已经存在,所以A就会放弃这个锁。